
Stargan&combogan多领域的图像转换
之前利用GAN进行图像生成的研究都是训练两个领域之间的图像转换生成,StarGAN和ComboGAN通过训练多领域转换模型来减少要进行多领域迁移所需要的模型数量和生成器判别器的个数,提升多领域图像转移的效率和便捷性。
StarGAN
论文:
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
github: StarGAN
论文思想
通过使用属性向量(one-hot)标签来进行多领域的图像转换,训练过程中随机选择一个目标域进行转换。网络只使用一个生成器和一个判别器。实验结果能够比基准模型DIAT、IcGAN、CycleGAN等有更好的生成效果。
LOSS
Loss 包含三项, 对抗loss, 类别loss, 重建loss.
对抗 loss
带梯度惩罚的Wasserstein GAN loss, 公式如下:
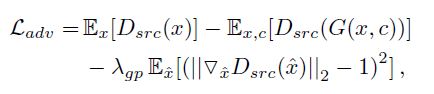
其中, \lamda_{gp} = 10
类别 loss
用真实图像来优化判别器,用生成图像来优化生成器。
用真实图像来优化判别器, Loss公式如下:
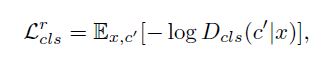
用生成图像来优化生成器, Loss公式如下:
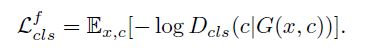
重建 loss
适用循环一致性损失函数, Loss公式如下:
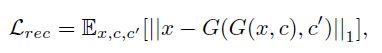
总 loss
由以上 Loss, 可得生成器和判别器的 loss 公式分别如下:
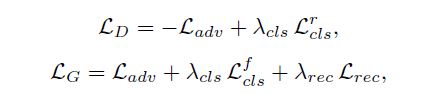
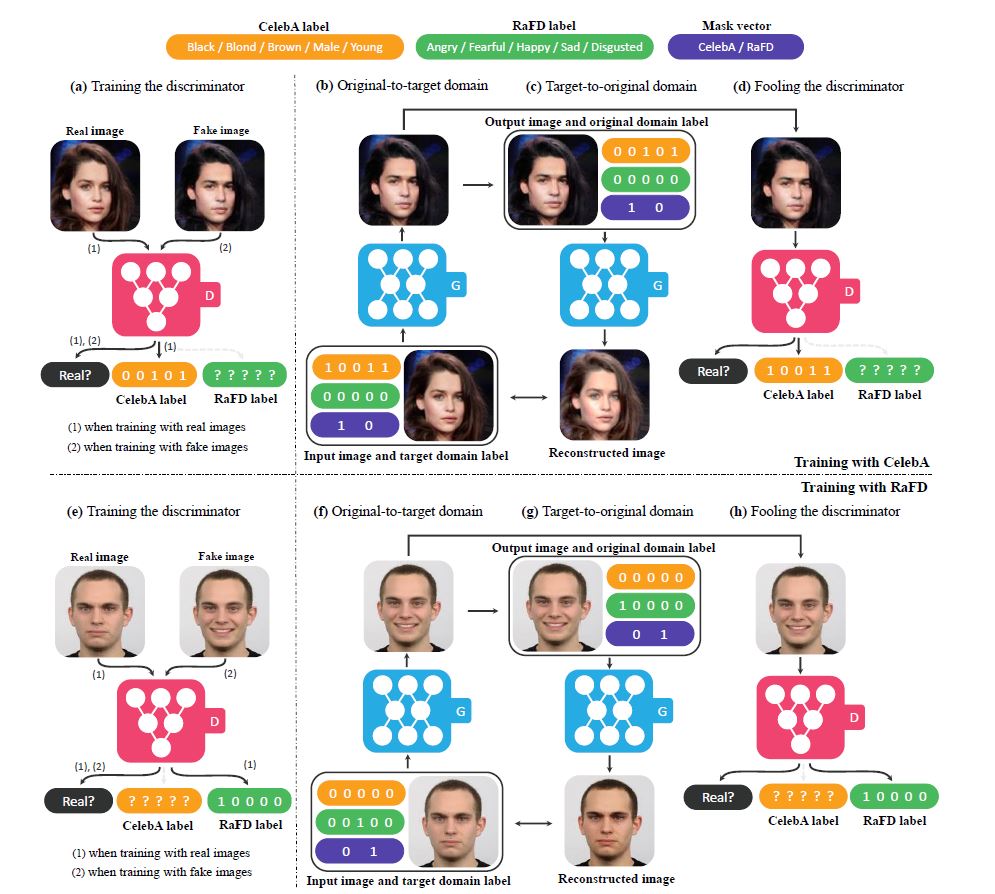
多数据集训练
向量标签的组成由CelebA数据集的属性和RaFD数据集的属性及数据集标签组成,是一个二维的one-hot编码。
在训练未开始前将属性向量标签信息连接到输入图像上作为输入数据。
具体的标签属性排列及训练过程如下图:
-
第一行示意图
在CelebA数据集上进行训练,CelebA label中有属性,RaFD属性全部无关,置为0,Mask Vector CelebA置1。
生成器将性别女棕色头发的人像转换到性别男黑色头发的目标域,对生成的图像再进行重建得到原来领域的生成图像。
判别器用真实的数据进行训练,只对已知的属性(由mask vector标识)进行loss最小化,将生成的图像输入D判别真假。图中左侧图示的CelebA label书写错误,应为 10011。
-
第二行示意图
第二行示意图是在RaFD数据集上,训练过程同在CelebA数据集上。
网络结构
stargan生成器结构如下:
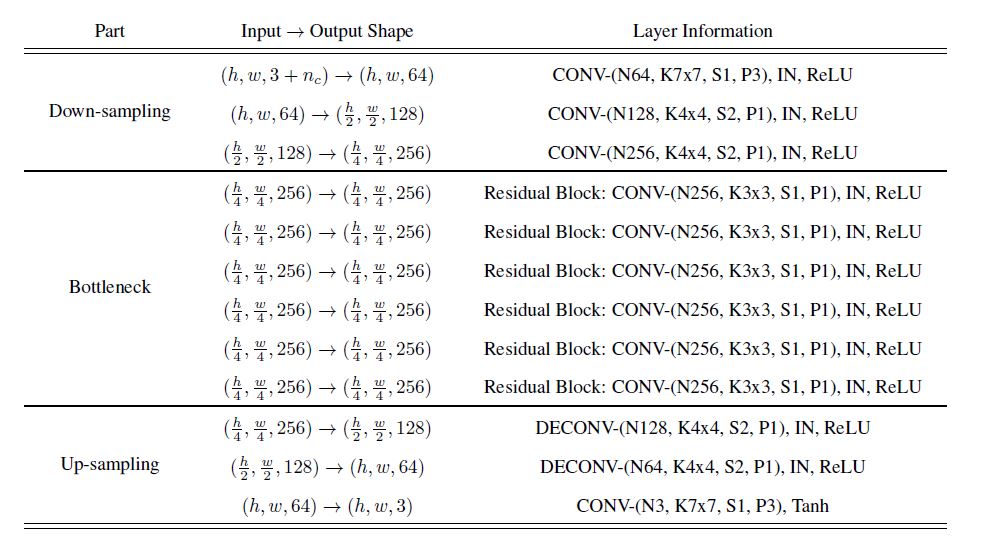
stargan生成器结构如下:
ComboGAN
论文:
ComboGAN: Unrestrained Scalability for Image Domain Translation
github 地址:ComboGAN
论文思想
ComboGAN与StarGAN相同,是要进行多领域的图像转换。
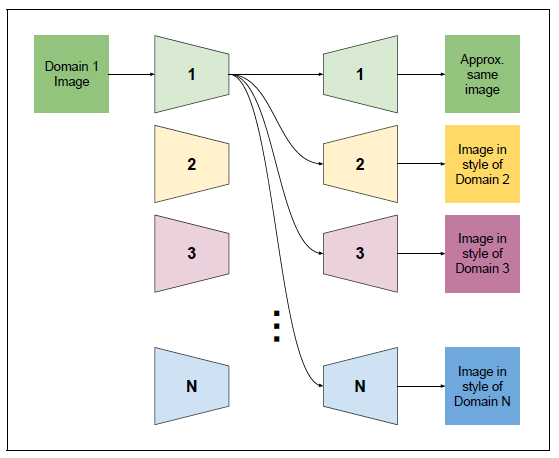
ComboGAN对CycleGAN进行改造,与StarGAN不同的是网络中生成器和判别器不再共用一个网络,而是在各自的领域建立各自的Encoder、Decoder和Discriminator。根据要转换的图像域来进行Encoder和Decoder的组合。
ComboGAN的Encoder与不同的Decoder进行匹配转换的示意图如下:
LOSS
与CycleGAN的loss相同。
训练
从所有的领域中随机挑选两个领域进行训练,重复进行n次。
训练时间与转换领域个数呈线性关系。
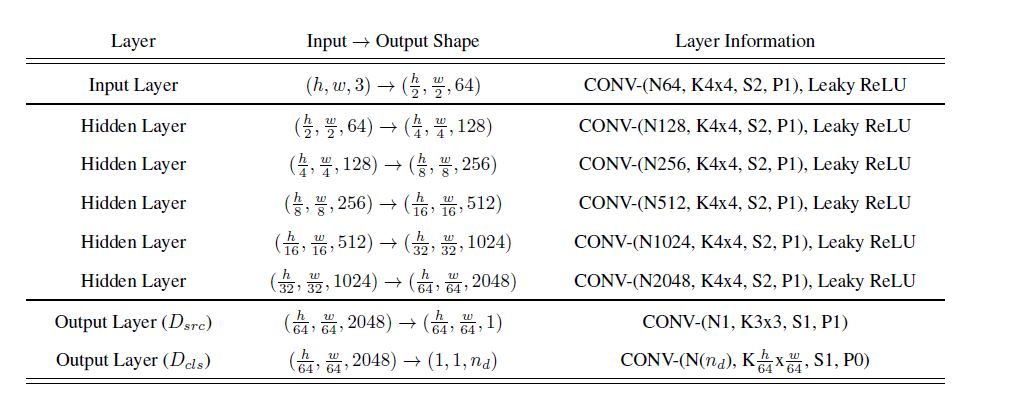
网络结构
ComboGAN的网络结构如下:
