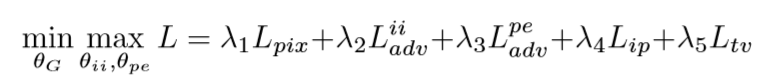多角度人脸生成
数据增强与人脸识别
在Iacopo等人的 Do We Really Need to Collect Millions of Faces for Effective Face Recognition? 一文中,对近年来人脸识别和数据的关系进行了总结,并提出和验证了利用数据增强方法对小数据集扩充后进行训练能够达到与当时最杰出的网络相当的效果。
由于训练数据集的爆炸性增长,人脸识别的正确率得到了很大的提升。通过收集和标记网络上的人脸数据不仅需要巨大的资金支持,从当前已有的人脸数据库的统计信息可知,数据库中图片数量的增长速度远远快于同一个人的图片数量,这意味着虽然数据变得越来越充沛,却很难找到许多的图片进行验证。
大量数据在人脸识别系统中训练面临的问题:人脸识别系统不仅需要辨识不同人,而且需要在一个人的不同姿态相貌下能够识别为同一个人。数据增强是解决这个问题的一个关键技术。
3D 方法
通过对头部模型的重建和纹理贴图贴合,得到人的三维渲染模型,接着进行表情角度表情等的变换并重新生成得到二维图像结果。
在此,在三维扫描重建中,对3DMM(3D Morphable Model)方法和SFS(Shape from Shading)方法进行介绍。
3DMM
三维形变模型将人脸看作一个线性空间,先用三维扫描的方式得到一个三维的人脸库,近似作为人脸模型空间的基底。人脸空间的基底是由形状向量 Si 和纹理向量 Ti 组成。对于给定的图像,求出关于空间基底的系数,接着经由人脸空间基底和对应的系数计算得到最后的模型。三维形变模型的构建流程由建立人脸空间基底和模型匹配重建两个部分组成。
SFS
Shape from shading是由Horn于1980年提出的,通过假定表面是Lambert表面,从单幅图像的渲染信息来恢复三维信息的一种方法。
在人脸的三维重建这一应用中,SFS方法是不断迭代优化的过程。三维重建时,一个固定的变换是通过人脸关键点与参考模型的对齐,接着计算参考模型平面的倾角和法向,最后计算出图像上的点的深度。
优点
生成过程可看成是人脸的二维网格拓扑结构进行拉伸缩放等操作后,映射到不同三维流形空间中,接着从不同的三维模型空间或者不同角度得到生成结果,能够一定程度上保证人的id不变性。
缺点
生成结果的自然逼真性较差。
gan 方法
方法简述
通过在两个不同状态的训练集合上进行训练,学得将图像从一个状态空间转换到另一个状态空间的映射。
优点
生成的图像自然逼真程度较好。
缺点
生成结果有较大的不确定性,对人的id不变性有影响。
TP-GAN
代码: TP-GAN 、 pytorch-TP-GAN
思路
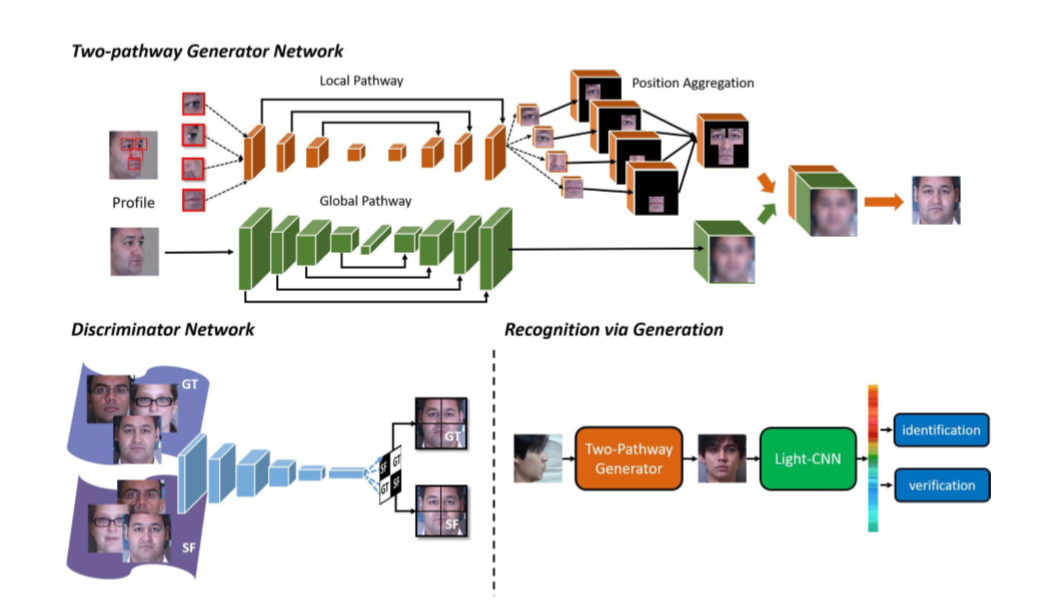
通过局部区域合成网络对五官的合成和整体区域合成网络对人脸整体的合成两个网络的结合(Two Way GAN)来获得整体的效果和局部较好的特征。此外,通过引入对抗损失、合成损失和特征保持损失的组合来约束网络训练。
网络的结构如下:
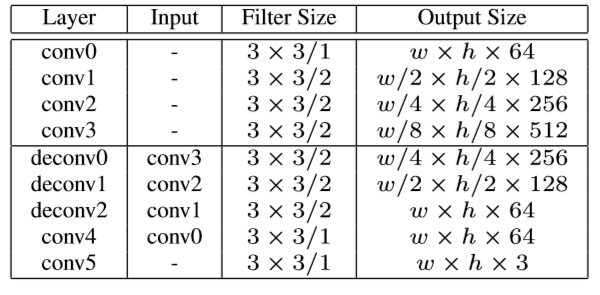
网络参数
如TP-GAN网络结构图所示,TP-GAN采用了Unet形式的内部网络结构。
全局网络的编码器卷积层后会跟着一个Residual block,在全局网络编码器的最后一个卷积层会多加三个Residual block。
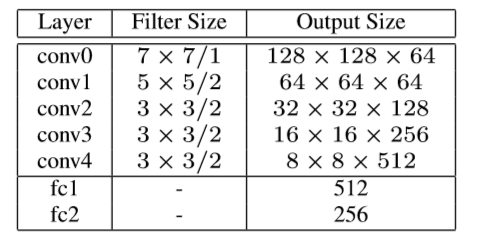
全局网络编码器的结构参数如下:
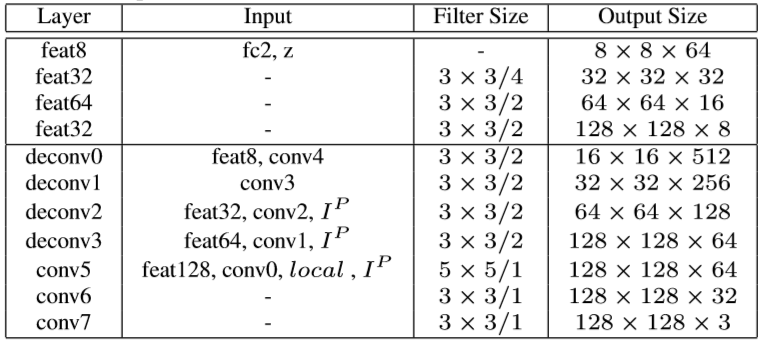
全局网络解码器的结构参数如下:
局部网络的参数如下:
Loss 约束
Loss 约束由四部分组合而成:像素级别的损失约束、对称损失约束、对抗损失约束、特征保持损失约束。
像素级别的损失约束
像素级损失约束将unet结构不同尺寸的图像内容转换生成结果的像素保持一致,具体损失函数如下:
![]()
对称损失约束
对称损失约束令合成的脸的在像素空间和拉普拉斯图像空间左右半边尽量保持一致,具体损失函数如下:
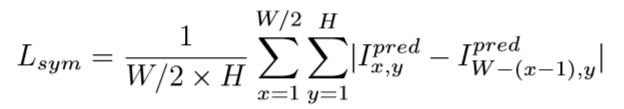
对抗损失约束
对抗损失约束用于辨别生成图像的真伪,具体的对抗损失函数如下:
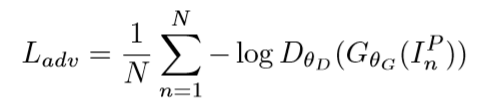
特征保持损失约束
特征保持约束让得到的生成图像与目标图像在经过判别器进行卷积降维后得到低级表征信息保持一致。
具体的损失函数如下:
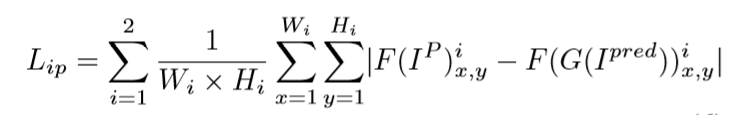
总特征约束
综上,得到的最后的loss 约束如下:
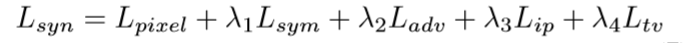
CAPG-GAN 网络
论文:
Pose-Guided Photorealistic Face Rotation
思路
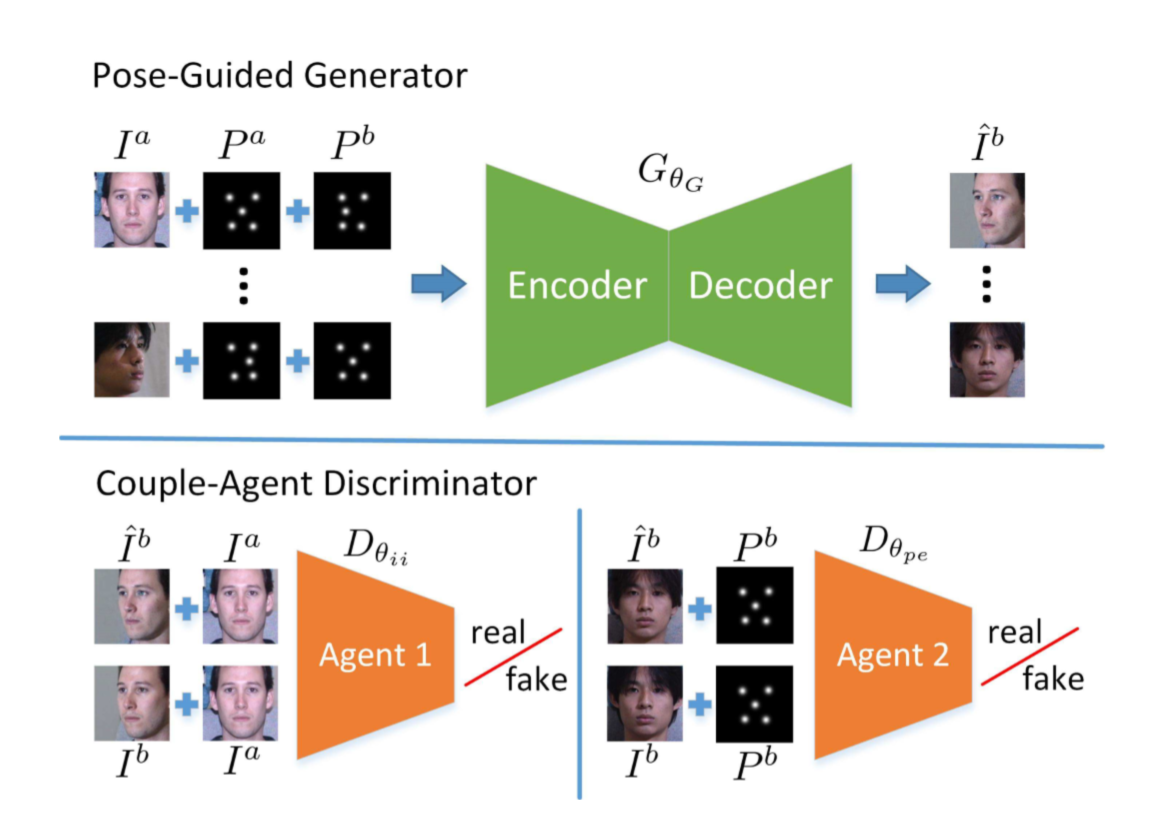
在生成器部分,在姿态转换中通过输入原始的五官位置信息和转换后图像的五官位置信息来控制和指引图像的生成。
在判别器部分,为了充分利用输入的五官位置先验信息,使用了双代理(Couple-Agent)判别器。判别器A与传统的GAN网络一致,通过把 {输入图像、目标图像}和 {输入图像,生成图像}输入判别器A来进行真伪判别;另一个判别器B将 {指引五官位置、目标图像}和 {指引五官位置,生成图像}输入判别器B进行真伪判别。
CAPG-GAN网络思路示意如下:
网络结构参数
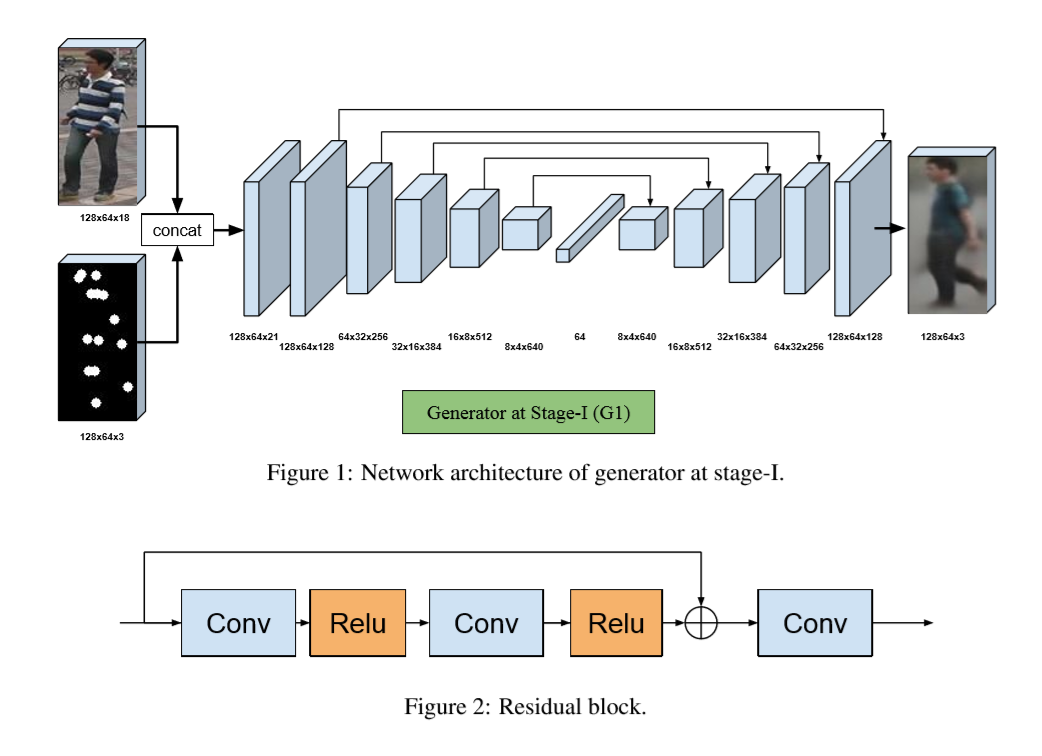
网络内部结构采用类似论文 Pose Guided Person Image Generation 的Unet和Residual Block卷积的结构。 Pose Guided Person Image Generation 网络的内部结构示意图如下:
网络的生成器的参数如下:
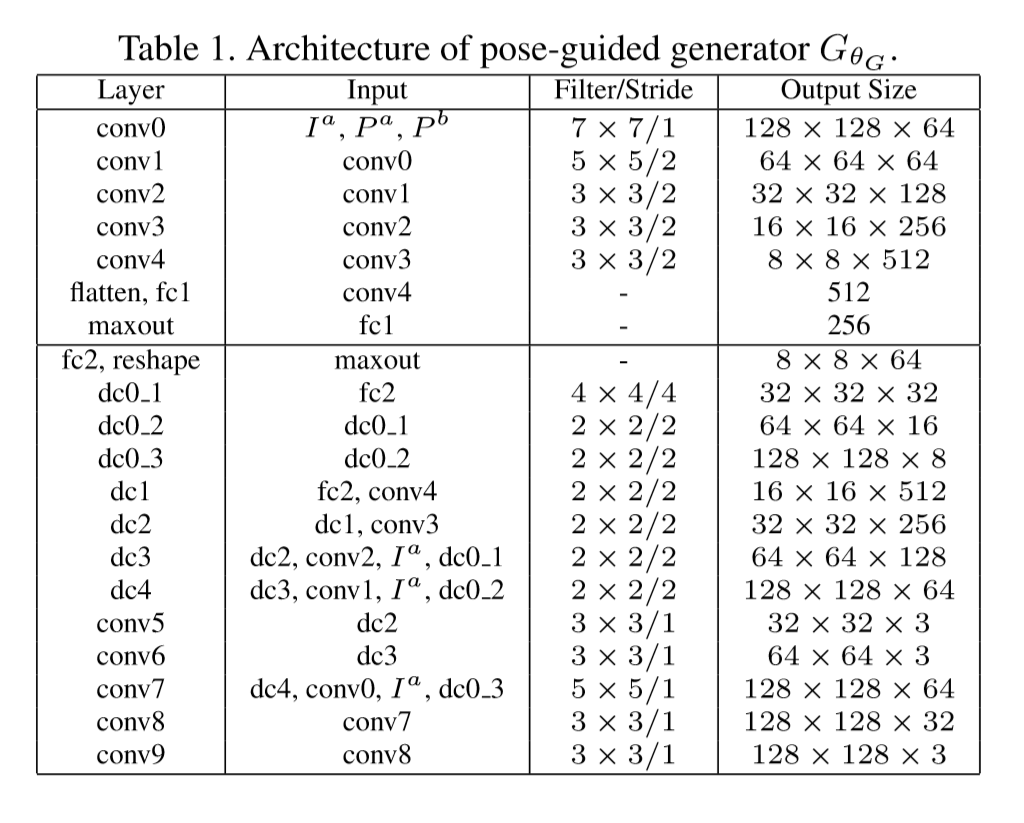
网络的判别器的参数如下:
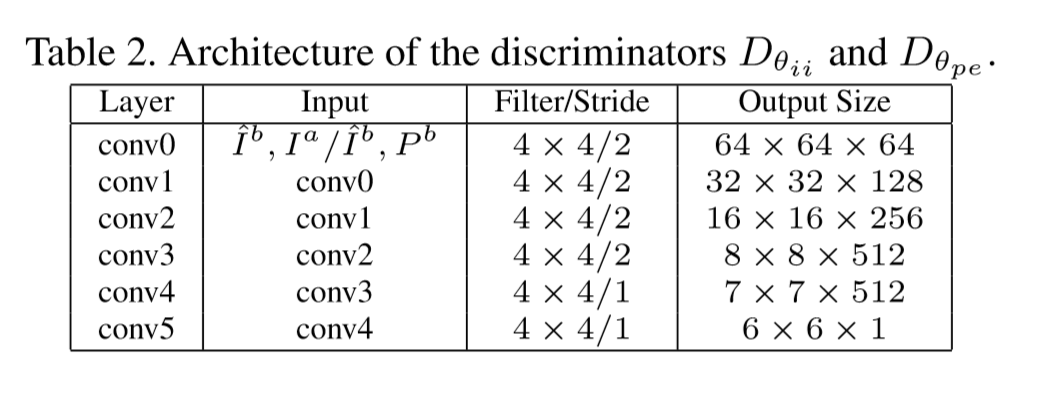
Loss 约束
网络的损失函数约束项包含四部分: 多层次像素级的损失约束、条件对抗损失约束、特征保持约束、全变化正则约束。
多层次像素级损失约束
多层次像素级损失约束将unet结构不同尺寸的图像内容转换生成结果的像素保持一致,具体损失函数如下:
![]()
条件对抗损失约束
条件对抗损失约束的形式和CGAN一致,是GAN的损失函数在指 定条件的形式。
DAPG-GAN网络在用于辨别{输入图像、目标图像}和 {输入图像,生成图像}图像对真伪的条件对抗损失函数如下:
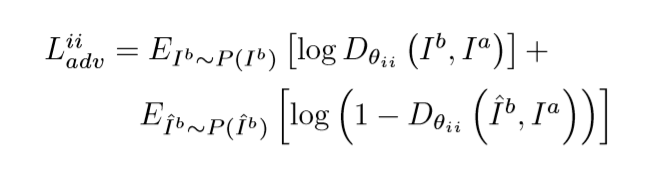
DAPG-GAN网络在用于辨别{指引五官位置、目标图像}和 {指引五官位置,生成图像}图像对真伪的条件对抗损失函数如下:
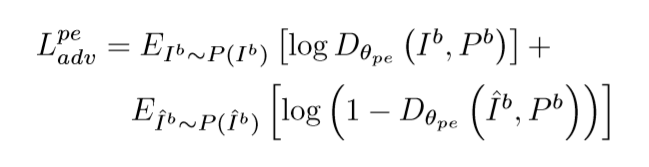
特征保持约束
特征保持约束让得到的生成图像与目标图像在经过判别器进行卷积降维后得到低级表征信息保持一致。 具体的损失函数如下:
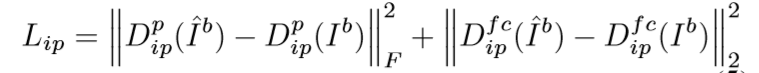
全变化正则化约束
全变化正则化约束通过让生成的相邻不同尺度的图像差距尽可能小来。 具体的损失函数如下:
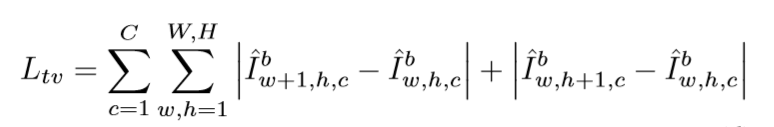
总 loss
综上,得到的最后的loss 约束如下: