
首页
K近邻法
发表于2017年02月27日 分类: statistical learning 标签: statistical learning
Table of Contents
基本的分类和回归方法 输入:实例的特征向量,对应于特征空间中的点 输出:实例的类别 通过多数表决等方法进行预测,不具有显式的学习过程。 三要素:k值的选择、距离度量、分类决策规则
k近邻法
对于新的输入实例,在训练集上找到与该实例最邻近的k个实例,这k个实例的多数属于哪个类,就把该实例分类为这个类
算法
k近邻法模型
模型对应于对特征空间的划分,由三个基本要素:距离度量、k值选择、分类决策规则 决定。
模型
距离度量
欧式距离
k 值选择
k 值过小,模型复杂,容易发生过拟合;k 值过大,模型简单。
分类决策规则
多数表决规则, 经验风险最小化
k近邻法的实现:kd树
提高k近邻搜索的效率,减少距离计算的次数。
构造kd树
平衡的kd树的搜索效率未必是最优的。
构造平衡kd树:对于深度为j的结点,选择x(l)为切分的坐标轴,l = j(mod k) + 1, 以该结点区域所有实例的x(l)坐标的中位数为切分点,切分为两个子区域,直至子区域中没有实例存在。
搜索kd树
最近邻搜索:首先找到包含目标点的叶结点;依次回退到父结点;不断查询与目标点最近的结点,当确定不可能存在更近的结点时终止。
Em算法及其推广
发表于2017年02月27日 分类: statistical learning 标签: statistical learning
Table of Contents
EM算法及其推广用于含有隐参数的概率模型参数的极大似然估计,或极大后验概率估计。 迭代由两步组成: E步:求期望 M步:求极大
EM算法的引入
最大似然估计需满足一个重要假设:采样是独立同分布的 最大后验概率估计:与最大似然估计类似,但最大的不同是最大后验概率估计融入了要估计量的先验分布在其中。故最大后验概率估计可以看做规则化的最大似然估计。
EM算法
定义Q函数:
完全数据的对数似然函数 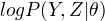 关于在给定观测数据Y和当前参数
关于在给定观测数据Y和当前参数 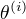 下对未观测数据Z的条件概率的期望称为Q函数, 即
下对未观测数据Z的条件概率的期望称为Q函数, 即
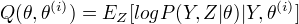
EM算法与选取的初值有关,选择不同的初值得到不同的参数估计值。
EM算法
输入:观测变量数据值Y,隐变量数据Z,联合分布 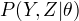 , 条件分布
, 条件分布 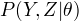 。
输出:模型参数
。
输出:模型参数 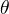 (1)选择参数
(1)选择参数 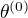 , 开始迭代
(2)E步:记
, 开始迭代
(2)E步:记 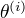 为第i次迭代参数 的估计值,在第i+1次迭代的E步,计算
为第i次迭代参数 的估计值,在第i+1次迭代的E步,计算
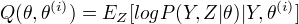
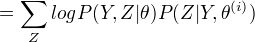 (3)M步:求使
(3)M步:求使 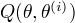 极大化的 ,确定第i+1次的估计值
极大化的 ,确定第i+1次的估计值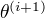
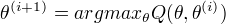 (4)重复第(2)步和第(3)步,直到收敛。
第二步中的Q函数是EM算法的核心。
(4)重复第(2)步和第(3)步,直到收敛。
第二步中的Q函数是EM算法的核心。
EM算法的导出
通过近似求解观测数据的对数似然函数的极大化问题来导出EM算法。看出EM算法的作用。 EM算法通过不断求解下界的极大化逼近求解对数似然函数极大化,不能保证找到全局最优值。
EM算法在非监督学习中的作用
EM算法可以用于生成模型的非监督学习。生成模型由联合概率分布P(X,Y)表示,可以认为非监督学习训练数据是联合分布产生的数据,X是观测数据,Y是未观测数据。
EM算法的收敛性
定理:设 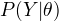 为观测数据的似然函数,
为观测数据的似然函数,
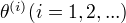 为EM算法得到的参数估计序列,
为EM算法得到的参数估计序列, 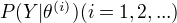 为对应的似然函数序列,则
为对应的似然函数序列,则 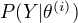 是单调递增的。
是单调递增的。
定理:…. 定理只能保证参数估计序列收敛到对数似然函数序列的稳定点,不能保证收敛到极大值点。 常用方法是选取几个不同的初值进行迭代,然后从得到的各个估计值加以比较,从中选择最好的。
EM算法在高斯混合模型中的应用
EM算法的一个重要应用:高斯混合模型的参数估计
高斯混合模型
高斯混合模型:
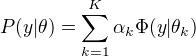 其中,
其中,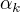 是系数,
是系数, 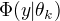 是高斯分布密度
是高斯分布密度
高斯混合模型参数估计的EM算法
1.明确隐变量,写出完全数据的对数似然函数
隐变量:反映观测数据 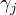 来自第k个分模型的未知数据,记为
来自第k个分模型的未知数据,记为 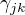 观测数据: 未观测数据
完全数据的似然函数:
观测数据: 未观测数据
完全数据的似然函数:
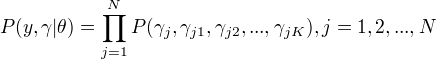
2.EM算法的E步,确定Q函数

计算 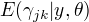 当前模型的第j个观测数据来自第k个分模型的概率, 记为
当前模型的第j个观测数据来自第k个分模型的概率, 记为 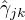 。
。
3.确定EM算法的M步。
用 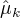 ,
, 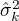 ,
, 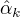 表示
表示 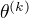 的各参数,通过偏导数为0求的值。
重复上述过程,直至对数似然函数不再有明显变化。
的各参数,通过偏导数为0求的值。
重复上述过程,直至对数似然函数不再有明显变化。
EM算法的推广
EM算法还可以解释为F函数的极大-极大算法,基于这个解释有若个变形和推广 GEM
F函数的极大-极大算法
定义: 隐变量数据Z的概率分布为 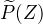 ,定义分布
,定义分布 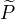 与参数 的函数
与参数 的函数 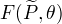 如下:
如下:
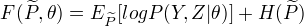 称为F函数, 式中
称为F函数, 式中 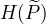 是分布 的熵。
是分布 的熵。
EM算法的一次迭代可由F函数的极大-极大算法实现
(1) 对固定的 ,求 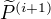 ,使得
,使得 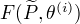 最大化。
(2) 对固定的 ,求 ,使得
最大化。
(2) 对固定的 ,求 ,使得 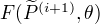 最大化。
最大化。
GEM算法
GEM算法1: EM算法的F函数方法表达
GEM算法2: 并不直接求极大,而是找到一个 使函数值变大。
GEM算法3: 参数 的维数d>=2时,将M步分解为d次条件极大化。
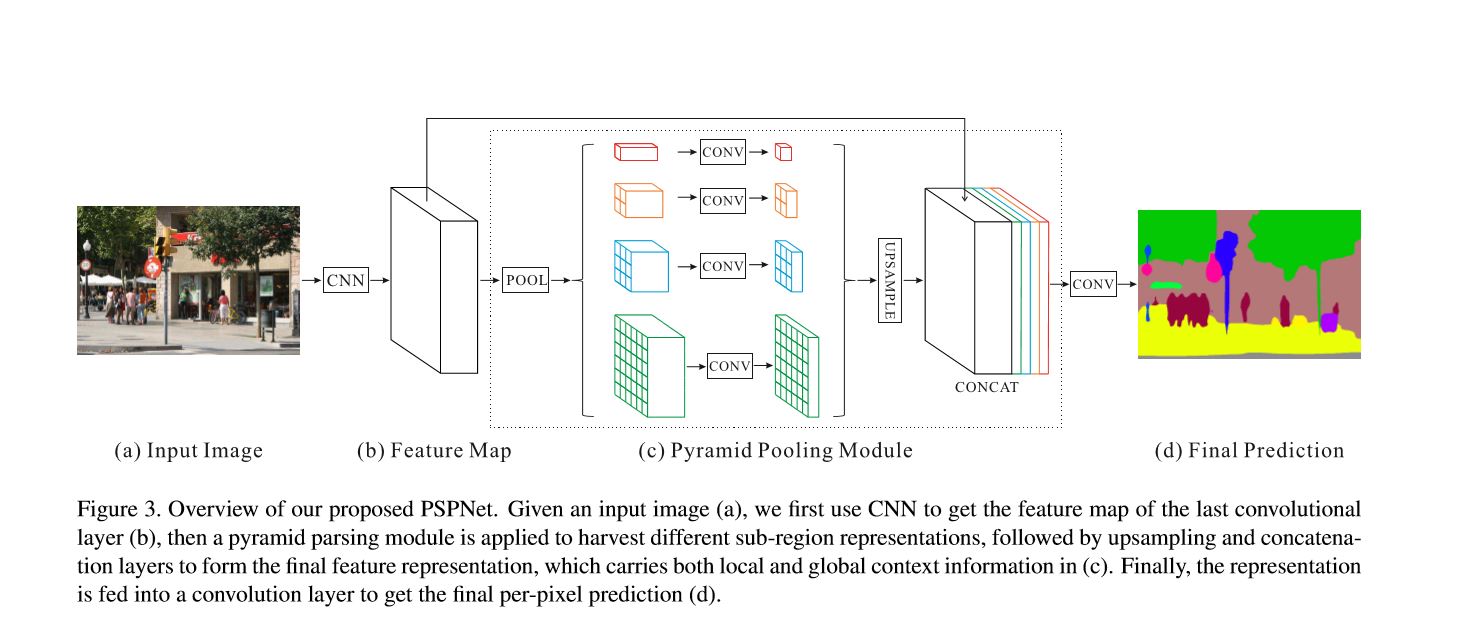
Pspnet
发表于2017年01月20日 分类: image segmentation 标签: deep learning image segmentation scene parsing
architecture
pyramid scene parsing network
resnet(extract feature) + pyramid pooling module + fcn + deeply supervised loss
overview of pspnet
图像分类网络
发表于2016年03月01日 分类: feature extraction 标签: feature extraction
LeNet-5 1998
conv-5 max pooling 2*2 2
[CONV-POOL-CONV-POOL-CONV-FC]
AlexNet 2012
simplified AlexNet architecture.
[CONV-POOL-NORM-CONV-POOL-NORM-CONV-CONV-CONV-POOL-FC-FC-FC]
VGGNet 2014
only 3*3 CONV stride 1 pad 1 , and 2*2 MAX POOL stride 2
GoogleLeNet 2014
inception module.
ResNet 2015
Revolution of Depth 152 layer.
faster than a VGGNet. Even though it has 8x more layers.
Typical architectures look like
[(CONV-RELU)*N-POOL?]*(FC-RELU)*K, SOFTMAX.
ResNet/GoogleLeNet chanllenge this paradigm.
Sift
发表于2016年03月01日 分类: feature extraction 标签: feature extraction
Scale-invariant feature transform 尺度不变特征变换
检测和描述局部点特征,在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变量。
用不同尺度(标准差)的高斯函数对图像进行平滑,然后比较平滑后图像的区别。
包换5个步骤:
1.构建尺度空间,检测极值点,获得尺度不变性。
2.特征点过滤并进行精确定位,剔除不稳定的特征点。
3.在特征点处提取特征描述符,为特征点分配方向。
4.生成特征描述子,利用特征描述符寻找匹配点。
5.计算变换参数。
Lstm&rnn
发表于2016年03月01日 分类: sequence learning 标签: sequence learning deep learning
(vanilla) Recurrent Neural Network
LSTM(长短期记忆人工神经网络)
是一种时间递归神经网络(RNN),适用于处理和预测时间序列中间隔和延迟比较长的重要事件。
四个S函数单元
input、forget、output.
输入信息、忘记信息、输出信息
LSTM
Bag Of Words
发表于2016年03月01日 分类: nlp 标签: nlp
bag-of-words(BOW)
信息检索领域常用的文档表示方法。
构造字典,统计每个单词出现的次数,形成文档向量。
缺点:未表示出单词的次序关系。
将BOW应用于图像表示。
(1)特征检测
利用SIFT算法提取视觉词汇
(2)单词表的构造
利用K-Means算法(基于样本间相似性度量的间接聚类方法) 将词性相近的词汇合并,作为单词表中的基本词汇。
(3)利用单词表中的词汇表示图像。
从图像中提取特征点,用单词表中的单词近似代替,统计词频。
Effective c++
发表于2016年02月04日 分类: c++ 标签: c++
让自己习惯C++
Rule 01: 视c++为一个语言联邦
次语言:c、Object-Oriented c++、Template C++、 STL
Rule 02: 尽量以const、enums、inline 代替 #define
编译器代替预处理器
/#define 不重视定义域,不提供封装性
enum{NumTurns = 5}; //"the enum hack"
tempplate<typename T>
inline void callWithMax(const T&a, const T& b){
f(a>b ? a : b); // f:调用函数
}
Rule 03: 尽可能地使用const
const 出现在号左边,被指物为常量, 出现在号右边,指针自身为常量
const_iterator
令函数返回一个常量值,降低因客户错误而造成的意外,而又不至于放低安全性和高效性。
Rational a, b, c;
if(a*b = c) //comparison error
将某些东西声明为const 可帮助编译器检测出错误语法
令non-const 版本调用const版本可以避免代码重复。
Rule 04: 确定对象被使用前已先被初始化
使用成员初始化列表来代替赋值操作。
设为default,成员初始化列表指定为空。
C++成员初始化次序
base classes > derived class
class 成员变量以声明的次序被初始化
晦涩错误:成员变量的初始化带有次序性,例:array 指定大小
C++对于定义在不同文件中的non-local static 对象的初始化顺序没有明确的顺序。
解决方法:通过函数调用(返回一个reference指向local static)代替non-local static的访问。
构造/析构/赋值运算
Rule 05: 了解C++默默编写并调用了哪些函数
class Empty{};
//is the same as
class Empty{
public:
Empty(){...}; //default 构造函数
~Empty(){...}; //析构函数
Empty(const Empty& rhs){...}; //copy函数
Empty &operator =(const Empty& rhs){...}; //copy assignment
}
Rule 06: 若不想使用编译器自动生成的函数,就该明确拒绝
class Uncopyable{
protected:
Uncopyable(){};
~Uncopyable(){};
private:
Uncopyable(const Uncopyable&)
Uncopyable & operator =(const Uncopyable &);
}
class HomeForSale: private Uncopyable{
}
Rule 07:为多态基类声明virtual析构函数
当derived class 对象经由一个base class 指针被删除,而该base class 带有一个non-virtual 析构函数,其结果未有定义,实际执行时通常发生的是对象的derived 成分没有被销毁。造成资源泄露、败坏的数据结构等。
若class不含virtual函数,意味着不是一个base class,不应将析构函数设为virtual。
实现virtual函数对象需要实现vptr,与其它语言不再具有移植性。
std::string 的析构函数是non-virtual。
不要企图继承标准容器或者带有non-virtual析构函数的class。
pure virtual 函数导致abstract classes。不能被实体化。
析构函数的运作方式:最深层的class的析构函数最先被调用。然后是其每一个上层的base class。
Rule 08:别让异常逃离析构函数
析构函数绝对不要吐出异常。如果一个被析构函数调用的函数可能抛出异常,析构函数应该捕捉异常并吞下或者结束程序。
如果需要对异常做出反应,那么应该提供一个普通函数执行该操作。
Rule 09:绝不在构造和析构函数中调用virtual函数
会带来意想不到的结果。与java和c#不同的地方。
调用virtual函数会下降到derive class 阶层。使用对象内部尚未初始化部分=危险
Rule 10:令operator= 返回一个 reference to *this
Rule 11: 在operator=中处理“自我赋值”
Widget& Widget::operator=(const Widget& rhs){
Widget tmp(rhs);
swap(rhs, tmp);
return *this;
}
Rule 12:复制对象时勿忘其每一个成分
为derive class 撰写copy 函数时要复制其base class 成分。那些成分往往是private,应调用base class 相应的函数进行复制。
不要尝试以某个copying函数实现另一个copying函数,应该将共同的机能放在第三个函数中。
资源管理
Rule 13:以对象管理类型资源
void f()
{
std::auto_ptr<Investment> pInv(createInvestment());
...
}
RAII
获得资源后立即放进管理对象。
管理对象运行析构函数确保资源释放。
auto_ptr被销毁时自动删除它的所指之物,勿让多个auto_ptr指向同一个对象。对象被删除多次 = 未定义行为
auto_ptr不寻常的性质:通过copy、copy assignment 复制他们,它们会变成null,而复制所得的指针将取得资源的唯一拥有权。
引用计数型智慧指针
void f()
{
...
std::tr1::share_ptr<Investment> pInv(createInvestment());
...
}
在c++11引入share_ptr
Rule 14:在资源管理类中小心copy行为
Rule 15:在资源管理类中提供对原始资源的访问
Rule 16:成对使用new 和delete时要采取相同形式
待续….
关于我
发表于2015年10月23日 分类: about 标签: 关于