
首页
多角度人脸生成
发表于2018年07月25日 分类: GAN 标签: GAN Data Augmentation
数据增强与人脸识别
在Iacopo等人的 Do We Really Need to Collect Millions of Faces for Effective Face Recognition? 一文中,对近年来人脸识别和数据的关系进行了总结,并提出和验证了利用数据增强方法对小数据集扩充后进行训练能够达到与当时最杰出的网络相当的效果。
由于训练数据集的爆炸性增长,人脸识别的正确率得到了很大的提升。通过收集和标记网络上的人脸数据不仅需要巨大的资金支持,从当前已有的人脸数据库的统计信息可知,数据库中图片数量的增长速度远远快于同一个人的图片数量,这意味着虽然数据变得越来越充沛,却很难找到许多的图片进行验证。
大量数据在人脸识别系统中训练面临的问题:人脸识别系统不仅需要辨识不同人,而且需要在一个人的不同姿态相貌下能够识别为同一个人。数据增强是解决这个问题的一个关键技术。
3D 方法
通过对头部模型的重建和纹理贴图贴合,得到人的三维渲染模型,接着进行表情角度表情等的变换并重新生成得到二维图像结果。
在此,在三维扫描重建中,对3DMM(3D Morphable Model)方法和SFS(Shape from Shading)方法进行介绍。
3DMM
三维形变模型将人脸看作一个线性空间,先用三维扫描的方式得到一个三维的人脸库,近似作为人脸模型空间的基底。人脸空间的基底是由形状向量 Si 和纹理向量 Ti 组成。对于给定的图像,求出关于空间基底的系数,接着经由人脸空间基底和对应的系数计算得到最后的模型。三维形变模型的构建流程由建立人脸空间基底和模型匹配重建两个部分组成。
SFS
Shape from shading是由Horn于1980年提出的,通过假定表面是Lambert表面,从单幅图像的渲染信息来恢复三维信息的一种方法。
在人脸的三维重建这一应用中,SFS方法是不断迭代优化的过程。三维重建时,一个固定的变换是通过人脸关键点与参考模型的对齐,接着计算参考模型平面的倾角和法向,最后计算出图像上的点的深度。
优点
生成过程可看成是人脸的二维网格拓扑结构进行拉伸缩放等操作后,映射到不同三维流形空间中,接着从不同的三维模型空间或者不同角度得到生成结果,能够一定程度上保证人的id不变性。
缺点
生成结果的自然逼真性较差。
gan 方法
方法简述
通过在两个不同状态的训练集合上进行训练,学得将图像从一个状态空间转换到另一个状态空间的映射。
优点
生成的图像自然逼真程度较好。
缺点
生成结果有较大的不确定性,对人的id不变性有影响。
TP-GAN
代码: TP-GAN 、 pytorch-TP-GAN
思路
通过局部区域合成网络对五官的合成和整体区域合成网络对人脸整体的合成两个网络的结合(Two Way GAN)来获得整体的效果和局部较好的特征。此外,通过引入对抗损失、合成损失和特征保持损失的组合来约束网络训练。
网络的结构如下:
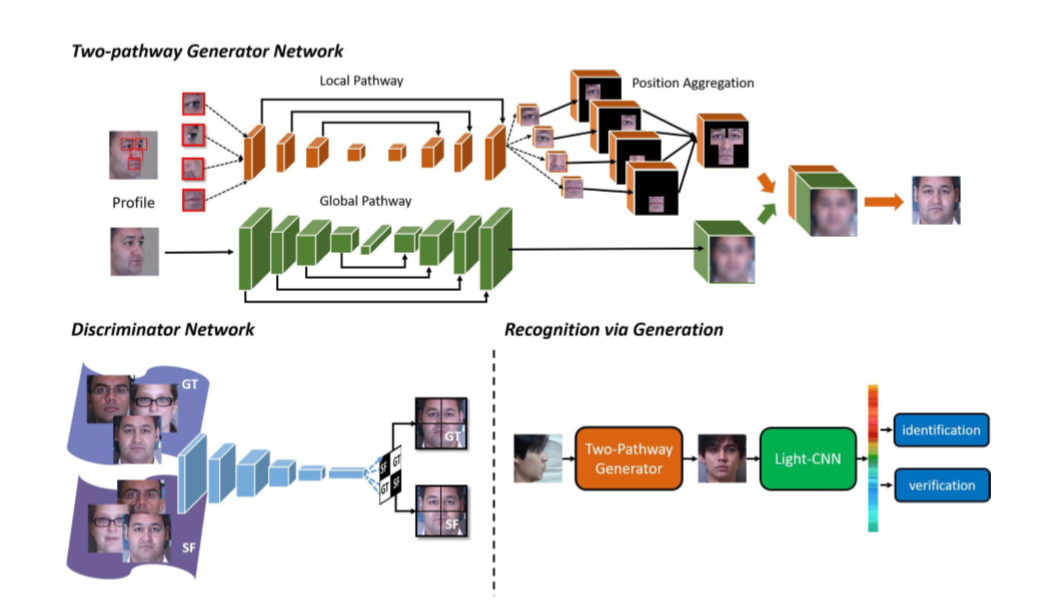
网络参数
如TP-GAN网络结构图所示,TP-GAN采用了Unet形式的内部网络结构。
全局网络的编码器卷积层后会跟着一个Residual block,在全局网络编码器的最后一个卷积层会多加三个Residual block。
全局网络编码器的结构参数如下:
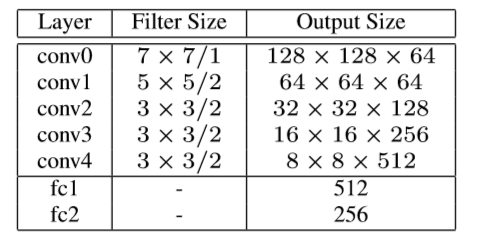
全局网络解码器的结构参数如下:
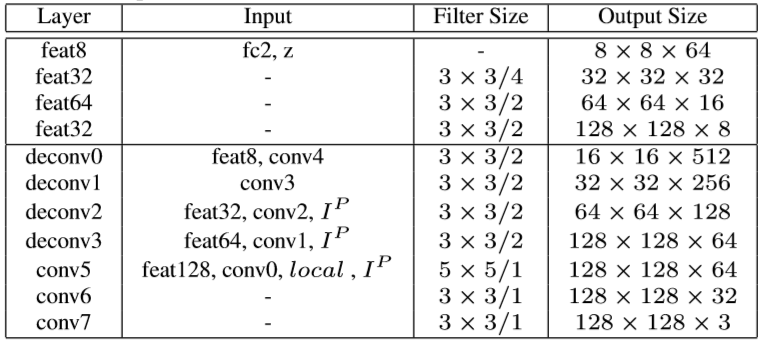
局部网络的参数如下:
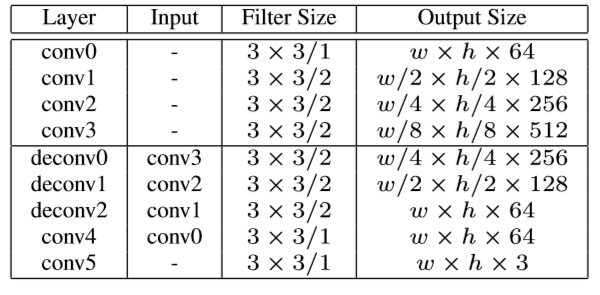
Loss 约束
Loss 约束由四部分组合而成:像素级别的损失约束、对称损失约束、对抗损失约束、特征保持损失约束。
像素级别的损失约束
像素级损失约束将unet结构不同尺寸的图像内容转换生成结果的像素保持一致,具体损失函数如下:
![]()
对称损失约束
对称损失约束令合成的脸的在像素空间和拉普拉斯图像空间左右半边尽量保持一致,具体损失函数如下:
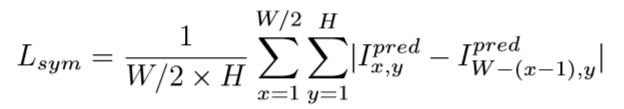
对抗损失约束
对抗损失约束用于辨别生成图像的真伪,具体的对抗损失函数如下:
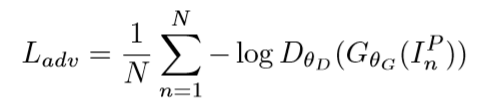
特征保持损失约束
特征保持约束让得到的生成图像与目标图像在经过判别器进行卷积降维后得到低级表征信息保持一致。
具体的损失函数如下:
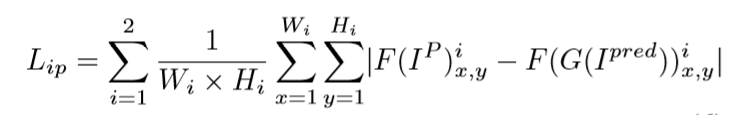
总特征约束
综上,得到的最后的loss 约束如下:
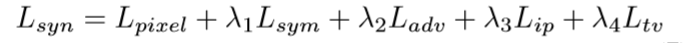
CAPG-GAN 网络
论文:
Pose-Guided Photorealistic Face Rotation
思路
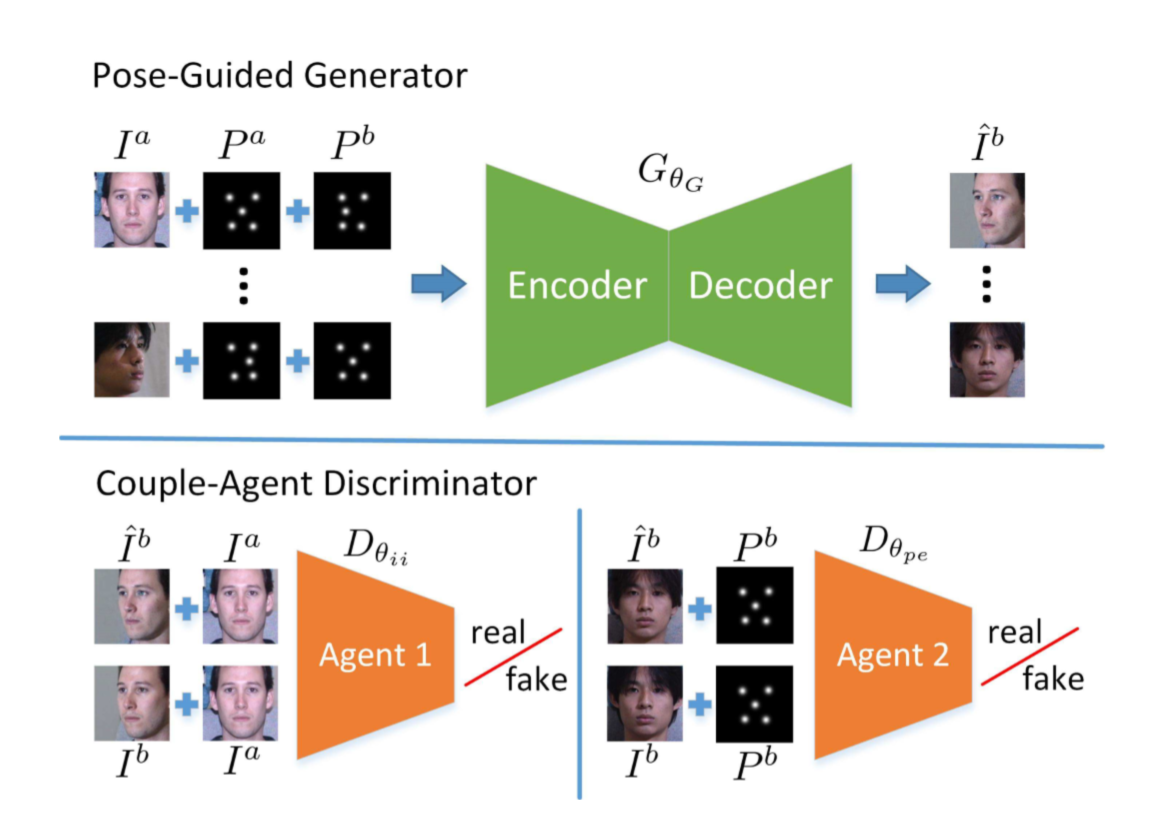
在生成器部分,在姿态转换中通过输入原始的五官位置信息和转换后图像的五官位置信息来控制和指引图像的生成。
在判别器部分,为了充分利用输入的五官位置先验信息,使用了双代理(Couple-Agent)判别器。判别器A与传统的GAN网络一致,通过把 {输入图像、目标图像}和 {输入图像,生成图像}输入判别器A来进行真伪判别;另一个判别器B将 {指引五官位置、目标图像}和 {指引五官位置,生成图像}输入判别器B进行真伪判别。
CAPG-GAN网络思路示意如下:
网络结构参数
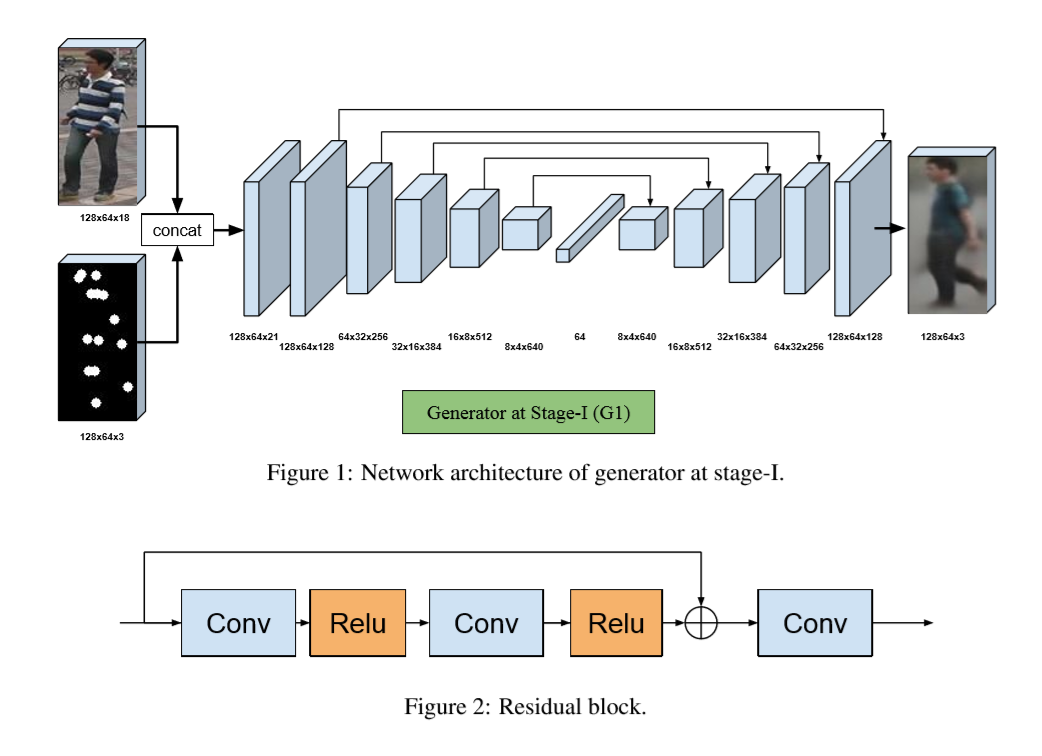
网络内部结构采用类似论文 Pose Guided Person Image Generation 的Unet和Residual Block卷积的结构。 Pose Guided Person Image Generation 网络的内部结构示意图如下:
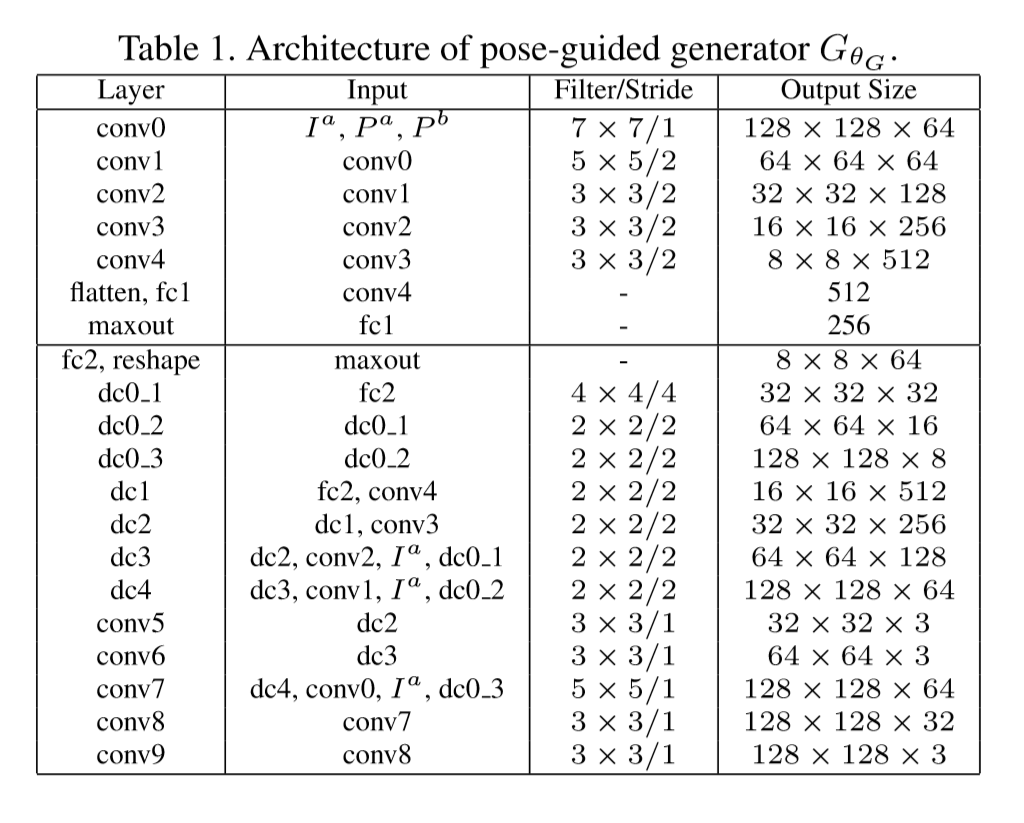
网络的生成器的参数如下:
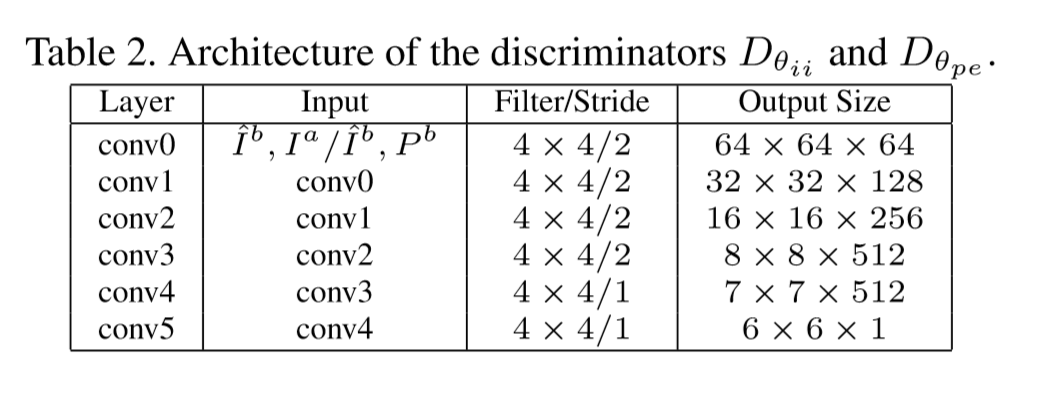
网络的判别器的参数如下:
Loss 约束
网络的损失函数约束项包含四部分: 多层次像素级的损失约束、条件对抗损失约束、特征保持约束、全变化正则约束。
多层次像素级损失约束
多层次像素级损失约束将unet结构不同尺寸的图像内容转换生成结果的像素保持一致,具体损失函数如下:
![]()
条件对抗损失约束
条件对抗损失约束的形式和CGAN一致,是GAN的损失函数在指 定条件的形式。
DAPG-GAN网络在用于辨别{输入图像、目标图像}和 {输入图像,生成图像}图像对真伪的条件对抗损失函数如下:
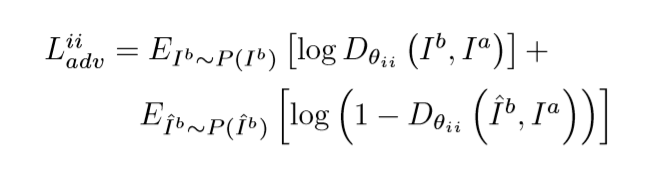
DAPG-GAN网络在用于辨别{指引五官位置、目标图像}和 {指引五官位置,生成图像}图像对真伪的条件对抗损失函数如下:
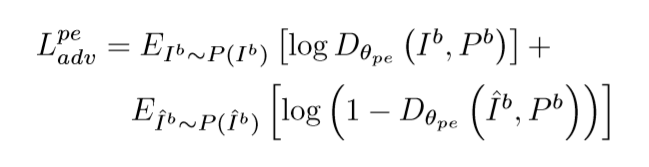
特征保持约束
特征保持约束让得到的生成图像与目标图像在经过判别器进行卷积降维后得到低级表征信息保持一致。 具体的损失函数如下:
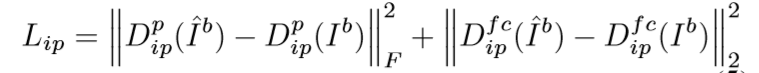
全变化正则化约束
全变化正则化约束通过让生成的相邻不同尺度的图像差距尽可能小来。 具体的损失函数如下:
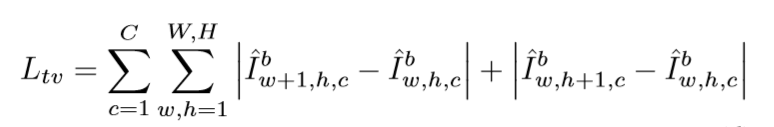
总 loss
综上,得到的最后的loss 约束如下:
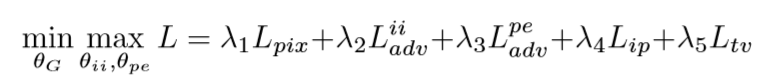
Cgan,icgan
发表于2018年01月28日 分类: GAN 标签: GAN DL
CGAN
论文:
Conditional Generative Adversarial Nets
github:
tensorflow-generative-model-collections
思路
在生成器和判别器都添加先验信息标签来条件生成指定类别的图像。
结构
CGAN的结构如下:
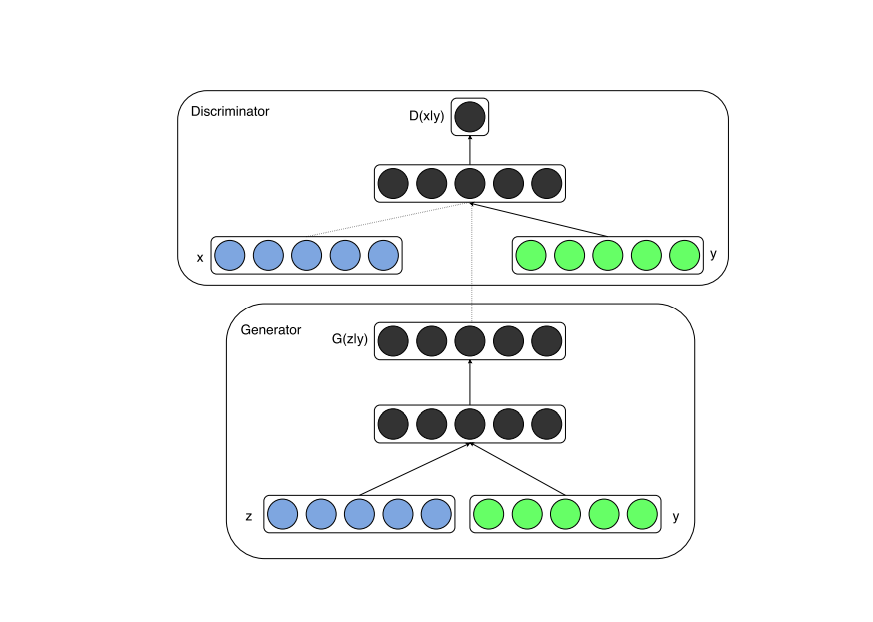
CGAN与GAN的具体结构的对比:
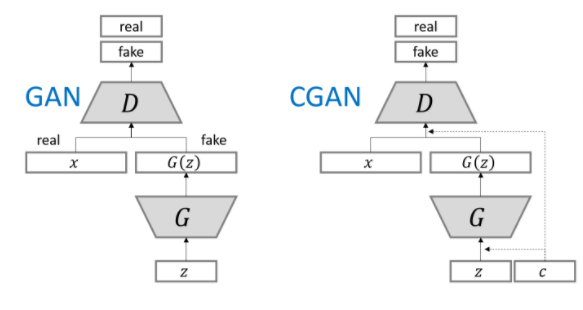
LOSS
gan的loss:
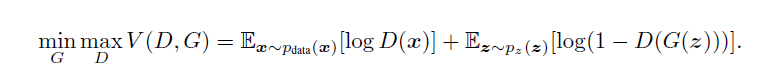
cgan的loss:
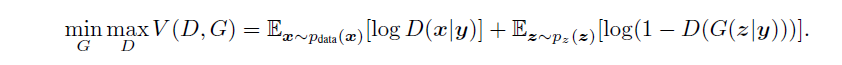
ICGAN
论文: Invertible Conditional GANs for image editing
github: ICGan-tensorflow
思路
将CGAN和Encoder 结合起来,将源图像的特征向量分离改变后重新生成新图像。通过Encoder,将一幅真实的图像编码为潜在编码z和特征向量y,改变条件向量y中的特征位,重新生成源图像改变特征后得到的新图像。
结构
ICGAN的结构如下:
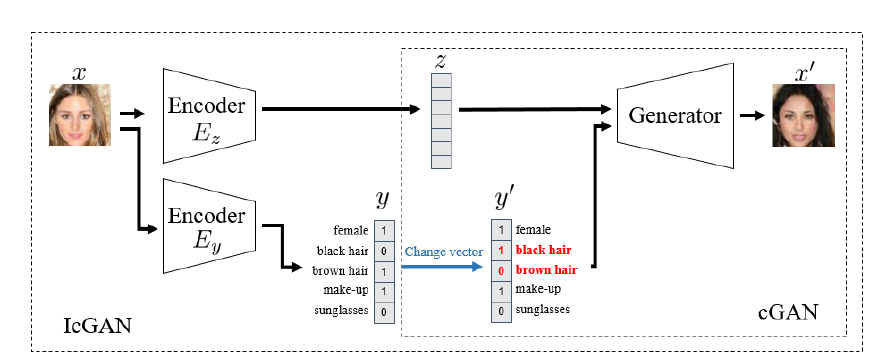
ICGAN中CGAN的具体结构:
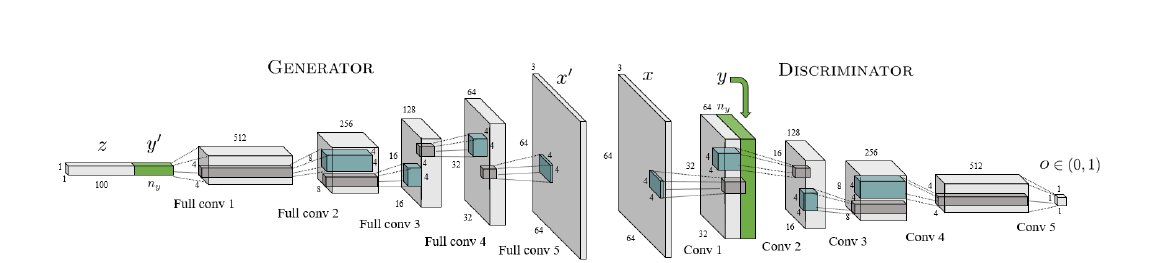
在生成器和判别器较早的引入了标签信息。
具体网络
生成器网络:

判别器结构:
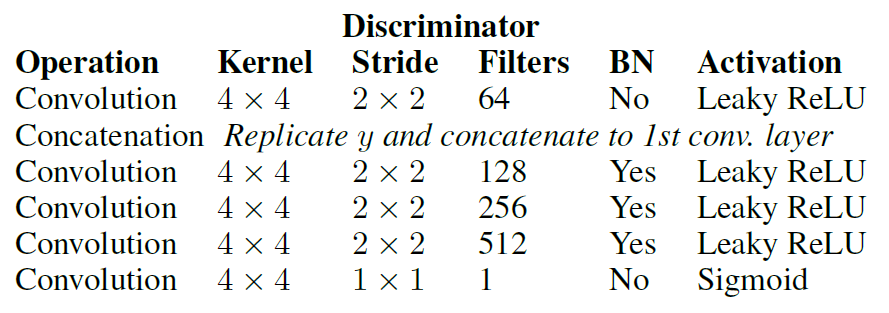
Encoder结构:

loss
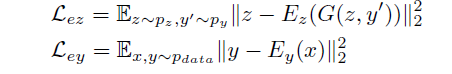
训练过程
IcGAN的训练包含3个步骤:
- 训练cGAN
- 用cGAN生成数据集A
- 用数据集A训练编码器Ez,使Ez能够将图像解析成对应的潜在编码z
- 用真实数据集训练编码器Ey,使Ey能够将真实图像解析出其对应的特征向量y
Tensorflow注意事项
发表于2018年01月20日 分类: attention 标签: tensorflow
tf.train.batch和tf.train.shuffle_batch
返回batch的样本和样本标签
顺序输出batch:
$ tf.train.batch([example, label], batch_size=batch_size, capacity=capacity)
乱序输出batch:
$ tf.train.shuffle_batch([example, label], batch_size=batch_size, capacity=capacity, min_after_dequeue
- 要保证 min_after_dequeue < capacity
sess.run()
每次执行sess.run()之后batch会更新,debug找了好久… T T
Docker命令
发表于2018年01月18日 分类: attention 标签: docker
上次用docker run运行了一个容器,现在需要挂载一个远程目录。原本run的容器权限不够,docker的运行忘得差不多,需要再花时间看,因而记录些东西以备忘。
命令简要说明
docker run
将镜像部署成容器,并且启动容器。每个容器创建后长期存在,故 docker run 命令只需要在第一次使用。
常见的参数:
- -i: 以交互模式运行容器,通常与 -t 同时使用;
- -t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用;
- -p: 在网络端口查看内容,示例:
-p 8888:8888 - -v: 挂载本地目录,示例:
-v host_abs_path:docker_abs_path - –name ““: 设置容器名称
- –privileged: 使容器拥有更高的权限,能够看到主机上的设备,能够挂载目录,可以在docker中运行docker等。
tensorflow gpu版的docker启动示例
$ sudo nvidia-docker run –privileged -name tf -it -p 8888:8888 -v ~/Documents/Workspace:~/Desktop/Workspace tensorflow/tensorflow:1.0.1-gpu-py3 bin/bash
docker start
启动运行已存在的容器
$ sudo docker start tf-docker
docker exec
在运行的容器中执行命令
$ sudo docker exec -it tf-docker /bin/bash
docker stop
停止正在运行的容器
$ sudo docker stop tf-docker
docker rm
删除容器
$ sudo docker rm tf-docker
docker rmi
删除镜像,删除镜像之前要停止所有的容器运行。
$ docker rmi
docker commit
将容器转变为镜像
$ sudo docker commit tf-docker tf-docker-image
docker ps [-a]
查看正在运行的容器容器信息。添加 -a 选项显示所有的容器,包含运行的和停止的。
为docker增加权限
这次遇到的问题是添加权限,由于容器创建的时候权限就已经确定,要添加权限就必须重新创建容器。因而需要先生存镜像接着重新创建容器。stackoverflow链接
$ sudo docker commit old-docker docker-image
$ sudo docker run -it –privileged docker-image /bin/bash
sshfs 远程主机文件映射
挂载命令:
$ sshfs user@hostname:path mount_point
卸载命令:
$ fusermount -u mountpoint
Jekyll输入
发表于2018年01月14日 分类: attention 标签: jekyll
支持格式
-
支持utf-8格式的markdown文件上传显示,gbk格式的内容无法正常编译显示。
-
gbk格式转utf-8: Ultraedit 另存为 选择 utf-8 格式
数学公式
-
在emacs 中以org-mode 编写,通过 ox-gfm 插件将org文件转换为markdown文件,转换过程需要latex环境的支持 使公式能够转换为图片。
ox-gfm说明:https://github.com/larstvei/ox-gfm
-
jekyll只能够解析位于”\assets\pics" 文件夹下的文件,不能够更换目录或添加子目录。 故需要将生成的公式图片置于此文件夹下,且生成markdown文件中的”ltximg"全部替换为”\assets\pics"
-
此外需要在markdown文件头部添加此文件所在分类及标签信息。
可通过在github的项目设置中查看是否有编译错误。
以上细节需要注意。
Stargan&combogan多领域的图像转换
发表于2018年01月13日 分类: GAN 标签: GAN DL
之前利用GAN进行图像生成的研究都是训练两个领域之间的图像转换生成,StarGAN和ComboGAN通过训练多领域转换模型来减少要进行多领域迁移所需要的模型数量和生成器判别器的个数,提升多领域图像转移的效率和便捷性。
StarGAN
论文:
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
github: StarGAN
论文思想
通过使用属性向量(one-hot)标签来进行多领域的图像转换,训练过程中随机选择一个目标域进行转换。网络只使用一个生成器和一个判别器。实验结果能够比基准模型DIAT、IcGAN、CycleGAN等有更好的生成效果。
LOSS
Loss 包含三项, 对抗loss, 类别loss, 重建loss.
对抗 loss
带梯度惩罚的Wasserstein GAN loss, 公式如下:
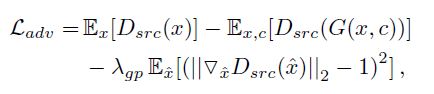
其中, \lamda_{gp} = 10
类别 loss
用真实图像来优化判别器,用生成图像来优化生成器。
用真实图像来优化判别器, Loss公式如下:
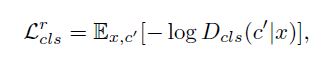
用生成图像来优化生成器, Loss公式如下:
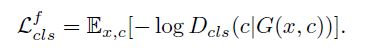
重建 loss
适用循环一致性损失函数, Loss公式如下:
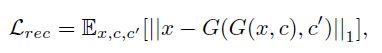
总 loss
由以上 Loss, 可得生成器和判别器的 loss 公式分别如下:
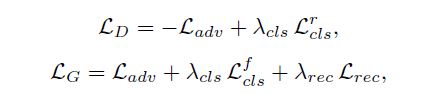
多数据集训练
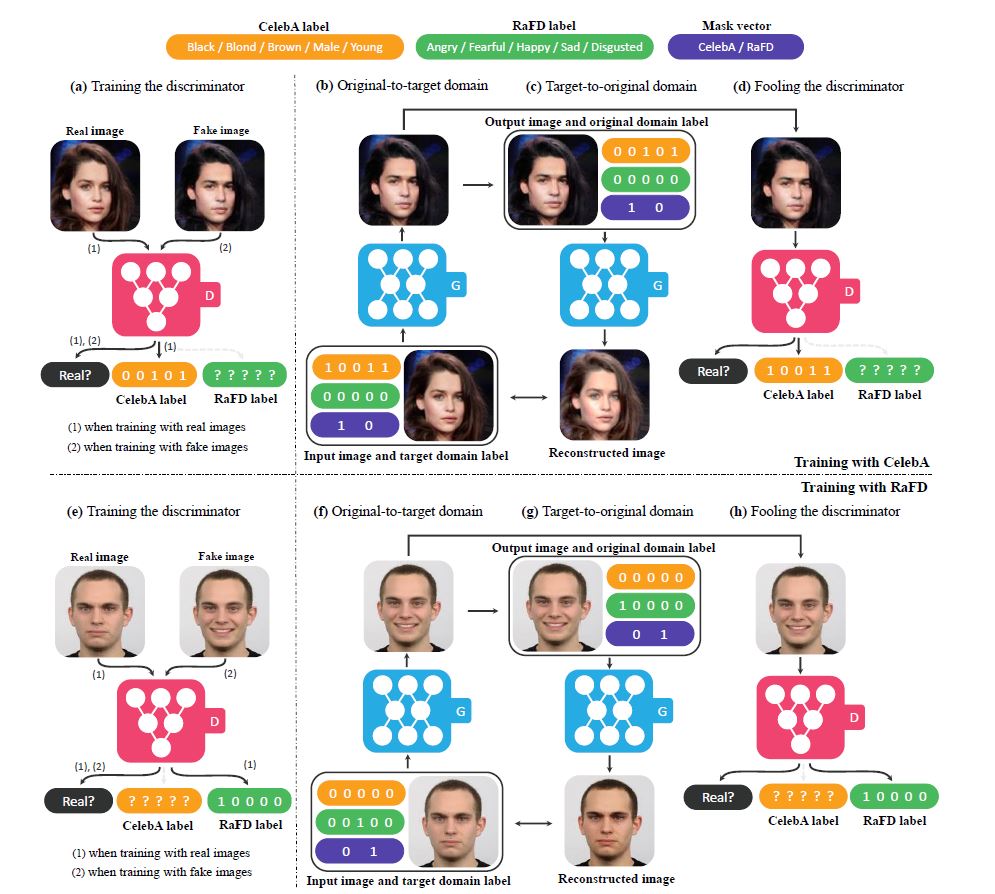
向量标签的组成由CelebA数据集的属性和RaFD数据集的属性及数据集标签组成,是一个二维的one-hot编码。
在训练未开始前将属性向量标签信息连接到输入图像上作为输入数据。
具体的标签属性排列及训练过程如下图:
-
第一行示意图
在CelebA数据集上进行训练,CelebA label中有属性,RaFD属性全部无关,置为0,Mask Vector CelebA置1。
生成器将性别女棕色头发的人像转换到性别男黑色头发的目标域,对生成的图像再进行重建得到原来领域的生成图像。
判别器用真实的数据进行训练,只对已知的属性(由mask vector标识)进行loss最小化,将生成的图像输入D判别真假。图中左侧图示的CelebA label书写错误,应为 10011。
-
第二行示意图
第二行示意图是在RaFD数据集上,训练过程同在CelebA数据集上。
网络结构
stargan生成器结构如下:
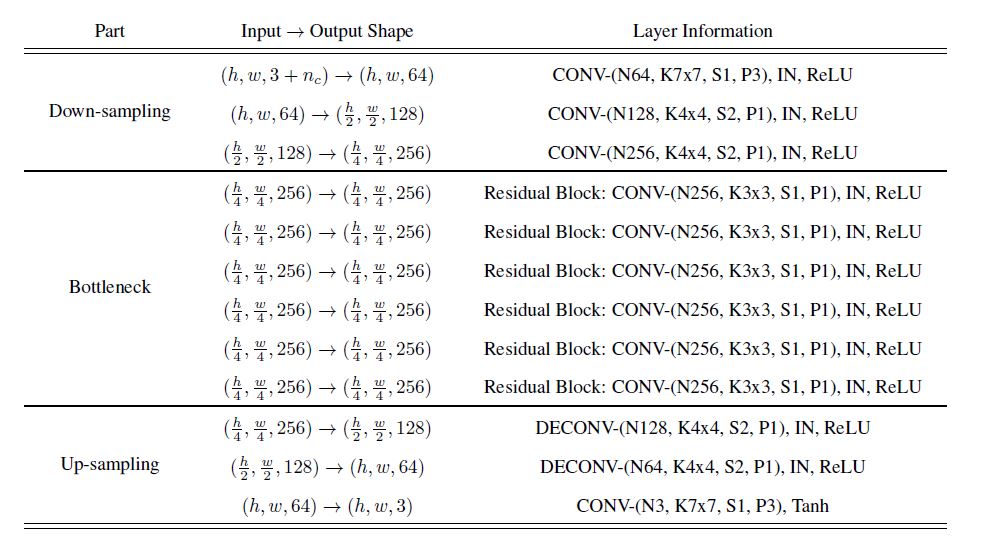
stargan生成器结构如下:
ComboGAN
论文:
ComboGAN: Unrestrained Scalability for Image Domain Translation
github 地址:ComboGAN
论文思想
ComboGAN与StarGAN相同,是要进行多领域的图像转换。
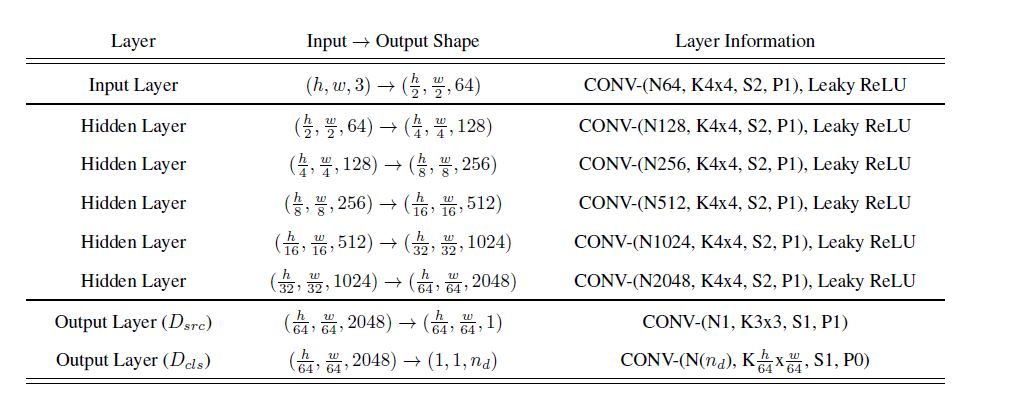
ComboGAN对CycleGAN进行改造,与StarGAN不同的是网络中生成器和判别器不再共用一个网络,而是在各自的领域建立各自的Encoder、Decoder和Discriminator。根据要转换的图像域来进行Encoder和Decoder的组合。
ComboGAN的Encoder与不同的Decoder进行匹配转换的示意图如下:
LOSS
与CycleGAN的loss相同。
训练
从所有的领域中随机挑选两个领域进行训练,重复进行n次。
训练时间与转换领域个数呈线性关系。
网络结构
ComboGAN的网络结构如下:

Nvidia使用gan生成高清晰图像
发表于2018年01月11日 分类: GAN 标签: GAN DL
nvidia 使用GAN生成高清晰图像论文:
PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION
github地址: progressve_growing_of_gans
贡献
-
提出新的训练的策略:对生成器和判别器从低分辨率开始,逐步地增长生成器和判别器的尺寸进行训练。
-
提出生成多样化图像的简单方法。
-
提出了一些减弱生成器和判别器不正当竞争的的实现细节。
-
提出gan图像生成的评判标准。
Loss
贡献点详解
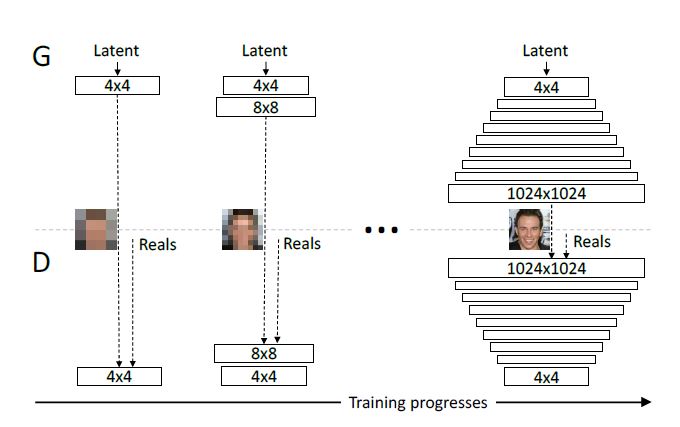
1.逐步增长的训练策略
从低分辨率开始训练,之后不断地在网络上添加层来进行更高分辨率的图像生成的训练。生成器和判别器的网络互为镜像,在整个训练过程中网络的所有层都保持在更新状态。
训练过程如下图:
分辨率提升和降低方法
相邻层尺寸放大及缩小一倍使用的方法:最近邻插值和平均池化
优点
-
在生成高分辨率的图像的过程中保持训练的稳定性
-
减少训练的时间
分辨率转换的过程如下:
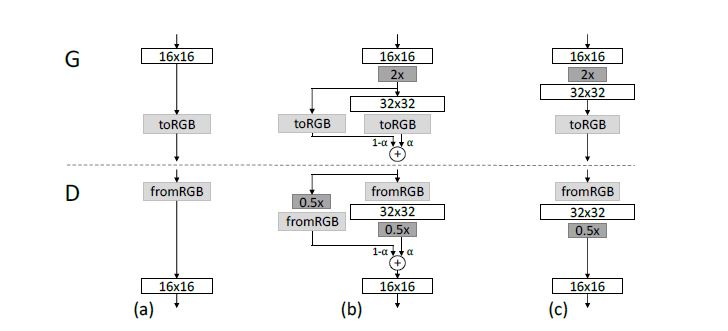
fromRGB、toRGB 颜色空间和特征空间的转换,使用1*1的卷积
使用类似残差模块的结构进行分辨率的转换。
2.使用小批量标准差来增加生成图像的多样性
GAN有只能捕捉到训练数据的一小部分子集的变化的特性
解决方法:小批量辨别
通过在判别器的后边添加一个小批量层次来实现
在文中对这种方法进行了简化来提高变化空间的大小
简化方案:
-
对每个特征在每个空间位置计算小批量数据的标准差
-
对所有的特征和所有的空间位置的第一步得到的计算值进行求平均得到一个值。
-
在每个空间位置将值进行重复得到一个常量值的特征层并将它连接到所有的特征空间上
此外,通过实验发现将特征层放在最后一层能得到最好的效果。
3.通过正则化来提升训练的稳定性
对权重进行动态正则化
通过对权重的动态正则化来保证所有权重的学习速率是相同的
在生成器中对特征向量进行像素级别的正则化
为了解决生成器和判别器在竞争中出现的信号规模失去控制的现象
解决方案:通过使用变化的“局部响应正则化”,公式如下
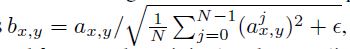
其中,b_{x, y} 是变化后的特征,a_{x, y} 是变化之前的特征。
4.新的图像变换的质量和变化程度的衡量机制
略
网络结构
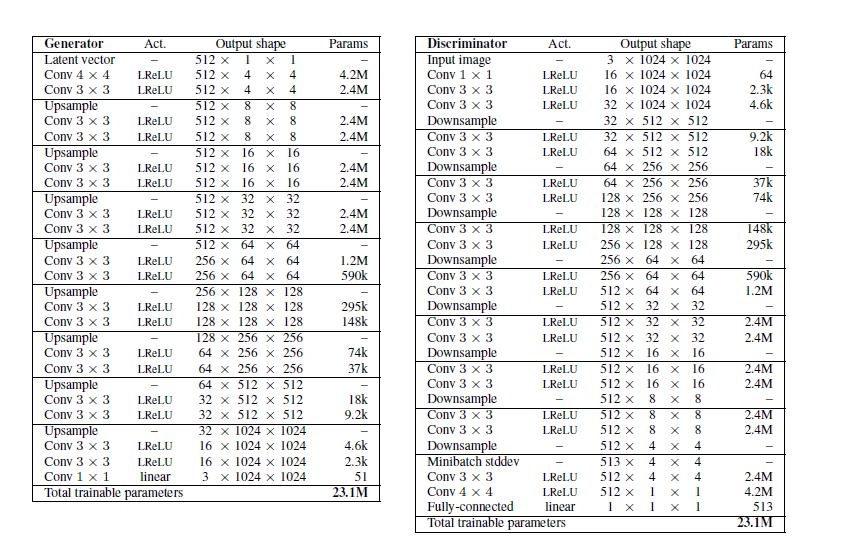
在celebA数据集上生成高清图像采用的网络结构如下图:
Genegan图像属性交换
发表于2017年12月10日 分类: GAN 标签: GAN DL
图像属性交换论文:
GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data
github地址:https://github.com/Prinsphield/GeneGAN
论文的主要思想:
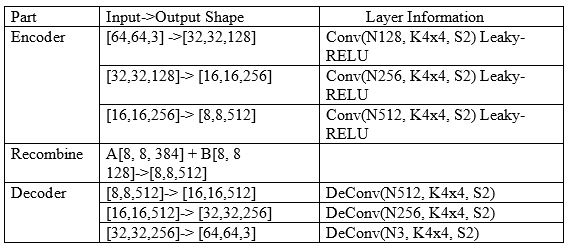
通过添加标签信息0,1,代表对应的特征的有无,将所有图片分为两类Ax, Be,对这两类分别用三层卷积层的Encoder进行编码得到特征fA, fx,fB,fe(对最后一层的特征进行切分,比例为3:1)。然后将特征对fA,fe 、fB,fx、 fA,fx、fB,fe输入Decoder,用三层反卷积成进行编码得到生成的图片Ae、Bx、Ax2、Be2。
网络结构
优点
不需要成对的同一个人有和没有相应特征的成对图片进行训练。添加Parallelogram Loss:
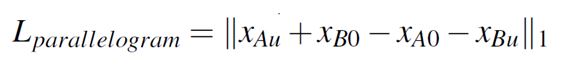
使生成图片和源图片的像素均值一致,以实现在两张图片的特征交换,确定特征的形态(比如微笑的程度,眼镜的款式),解决以往Gan生成特征的随机性问题。
不足
Reconstruction loss 较高,引起训练不稳定及图像质量不高的问题;特征交换效果不好。
Yolo
发表于2017年03月18日 分类: object detection 标签: deep learning object detection
Introduction
current detection system repurpose classifiers to perform detection.
DPM: sliding window
R-CNN: region propoal + classifier
YOLO Detection System
1.resizes the input size to 488*488.
2.runs a single convolutional network on the image.
3.thresholds the resulting detection.
benefit
1.fast. 2.reason globally about the image when making predictions. 3.learns generalizable representations of object.
Unified Detection
divides the input image into an SS grid.
Each grid predicts B bounding boxes. Each bounding box consists of 5 predictions: x, y, w, h, confidence and C conditional class probabilities.
confidence: predicts the intersection over union between the predicted box and the ground truth.
SS(B5 + C) tensor.
output: SSC tensor.
Network Design
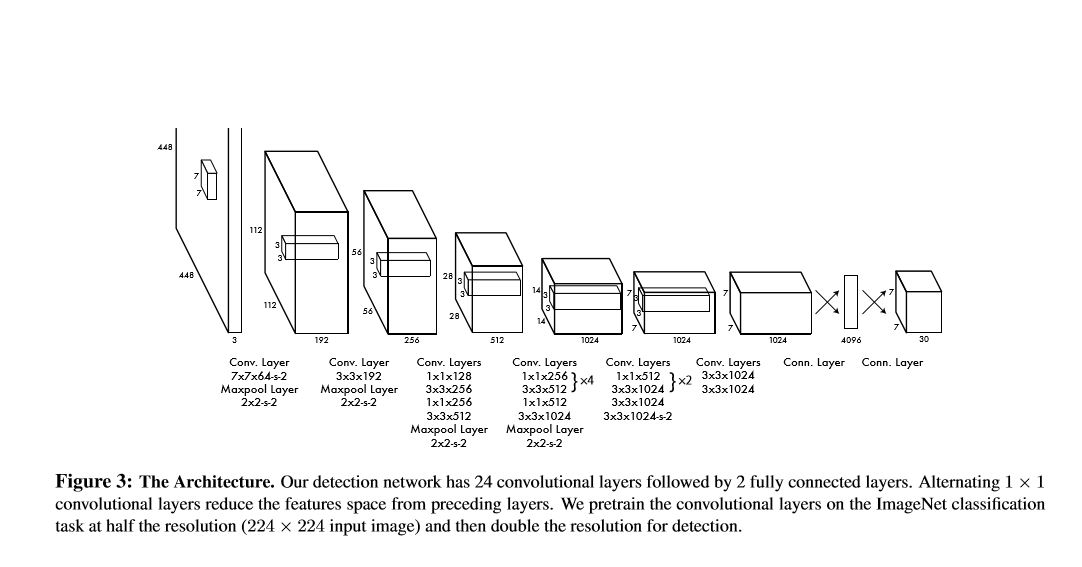 fast-yolo uses a neural network with fewer convolutional layers and fewer fiflters in those layers.
fast-yolo uses a neural network with fewer convolutional layers and fewer fiflters in those layers.
Limitations of YOLO
1.struggles with small objects.
2.struggles to generalize to objects in new or unuasal aspect ratios or configurations.
- A small error in a small box has a greater effect on IOU compared to a large box.
main source of error: incorrect localizations.
Conclusion
real-time object detection. simple and can trained directly on full images.
Unlike classifier-based approaches
1.YOLO is trained on a loss function that directly corresponds to detection performance
2.the entire model is trained jointly.
Rcnn演变
发表于2017年03月05日 分类: object detection 标签: deep learning object detection
rcnn
region proposal: selective search 约两千个框
分类:svm
回归:bounding box 回归
fast rcnn
roi pooling 层:将原图中的坐标映射到最后特征层上的坐标,共享特征提取网络,减少了特征提取部分的重复计算过程。
region proposal: selective search
分类:全连接+softmax
faster rcnn
region proposal: region proposal network
实现端到端的目标检测